Expert Verified, Online, Free.
You have 20 Azure SQL databases provisioned by using the vCore purchasing model.
You plan to create an Azure SQL Database elastic pool and add the 20 databases.
Which three metrics should you use to size the elastic pool to meet the demands of your workload? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Correct Answer:
ACE
🗳️
CE: Estimate the vCores needed for the pool as follows:
For vCore-based purchasing model: MAX(<Total number of DBs X average vCore utilization per DB>, <Number of concurrently peaking DBs X Peak vCore utilization per DB)
A: Estimate the storage space needed for the pool by adding the number of bytes needed for all the databases in the pool.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/elastic-pool-overview
DRAG DROP -
You have SQL Server 2019 on an Azure virtual machine that contains an SSISDB database.
A recent failure causes the master database to be lost.
You discover that all Microsoft SQL Server integration Services (SSIS) packages fail to run on the virtual machine.
Which four actions should you perform in sequence to resolve the issue? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct.
Select and Place: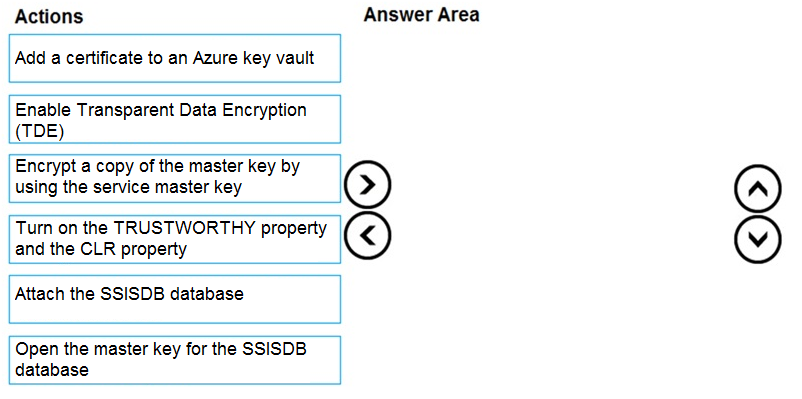
Correct Answer:
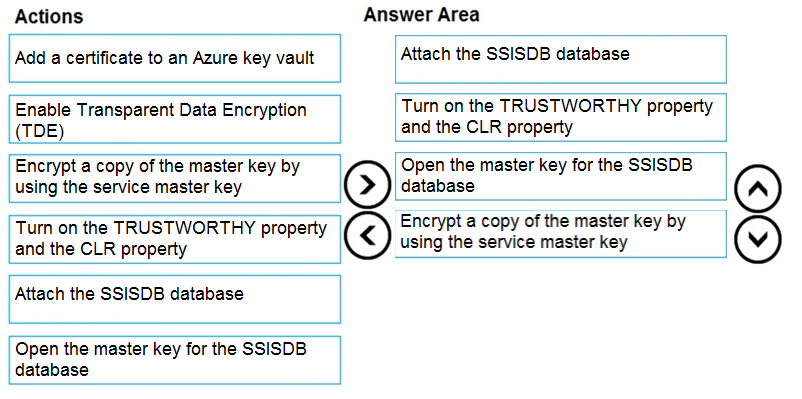
Step 1: Attach the SSISDB database
Step 2: Turn on the TRUSTWORTHY property and the CLR property
If you are restoring the SSISDB database to an SQL Server instance where the SSISDB catalog was never created, enable common language runtime (clr)
Step 3: Open the master key for the SSISDB database
Restore the master key by this method if you have the original password that was used to create SSISDB. open master key decryption by password = 'LS1Setup!' --'Password used when creating SSISDB'
Alter Master Key Add encryption by Service Master Key
Step 4: Encrypt a copy of the master key by using the service master key
Reference:
https://docs.microsoft.com/en-us/sql/integration-services/catalog/ssis-catalog
You have an Azure SQL database that contains a table named factSales. FactSales contains the columns shown in the following table.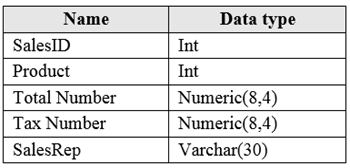
FactSales has 6 billion rows and is loaded nightly by using a batch process. You must provide the greatest reduction in space for the database and maximize performance.
Which type of compression provides the greatest space reduction for the database?
Correct Answer:
D
🗳️
Columnstore tables and indexes are always stored with columnstore compression. You can further reduce the size of columnstore data by configuring an additional compression called archival compression.
Note: Columnstore ג€" The columnstore index is also logically organized as a table with rows and columns, but the data is physically stored in a column-wise data format.
Incorrect Answers:
B: Rowstore ג€" The rowstore index is the traditional style that has been around since the initial release of SQL Server.
For rowstore tables and indexes, use the data compression feature to help reduce the size of the database.
C: Columnstore compression is less compressed compared to columnstore archival compression.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/data-compression/data-compression
You have a Microsoft SQL Server 2019 database named DB1 that uses the following database-level and instance-level features.
✑ Clustered columnstore indexes
✑ Automatic tuning
✑ Change tracking
✑ PolyBase
You plan to migrate DB1 to an Azure SQL database.
What feature should be removed or replaced before DB1 can be migrated?
Correct Answer:
B
🗳️
This table lists the key features for PolyBase and the products in which they're available.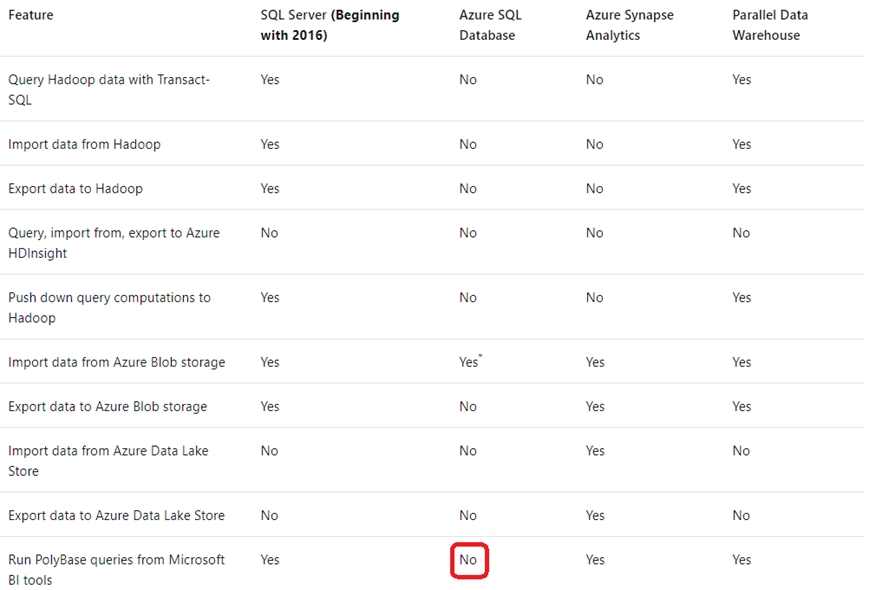
Incorrect Answers:
C: Change tracking is a lightweight solution that provides an efficient change tracking mechanism for applications. It applies to both Azure SQL Database and SQL
Server.
D: Azure SQL Database and Azure SQL Managed Instance automatic tuning provides peak performance and stable workloads through continuous performance tuning based on AI and machine learning.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-versioned-feature-summary
You have a Microsoft SQL Server 2019 instance in an on-premises datacenter. The instance contains a 4-TB database named DB1.
You plan to migrate DB1 to an Azure SQL Database managed instance.
What should you use to minimize downtime and data loss during the migration?
Correct Answer:
D
🗳️
Azure Database Migration Service can do online migrations with minimal downtime.
Reference:
https://docs.microsoft.com/en-us/azure/dms/dms-overview
HOTSPOT -
You have an on-premises Microsoft SQL Server 2016 server named Server1 that contains a database named DB1.
You need to perform an online migration of DB1 to an Azure SQL Database managed instance by using Azure Database Migration Service.
How should you configure the backup of DB1? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: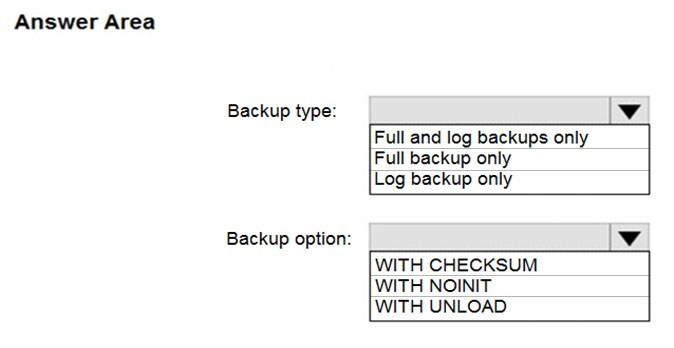
Correct Answer:
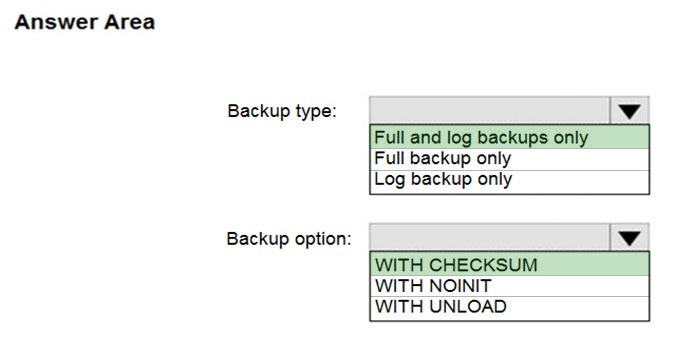
Box 1: Full and log backups only
Make sure to take every backup on a separate backup media (backup files). Azure Database Migration Service doesn't support backups that are appended to a single backup file. Take full backup and log backups to separate backup files.
Box 2: WITH CHECKSUM -
Azure Database Migration Service uses the backup and restore method to migrate your on-premises databases to SQL Managed Instance. Azure Database
Migration Service only supports backups created using checksum.
Incorrect Answers:
NOINIT Indicates that the backup set is appended to the specified media set, preserving existing backup sets. If a media password is defined for the media set, the password must be supplied. NOINIT is the default.
UNLOAD -
Specifies that the tape is automatically rewound and unloaded when the backup is finished. UNLOAD is the default when a session begins.
Reference:
https://docs.microsoft.com/en-us/azure/dms/known-issues-azure-sql-db-managed-instance-online
DRAG DROP -
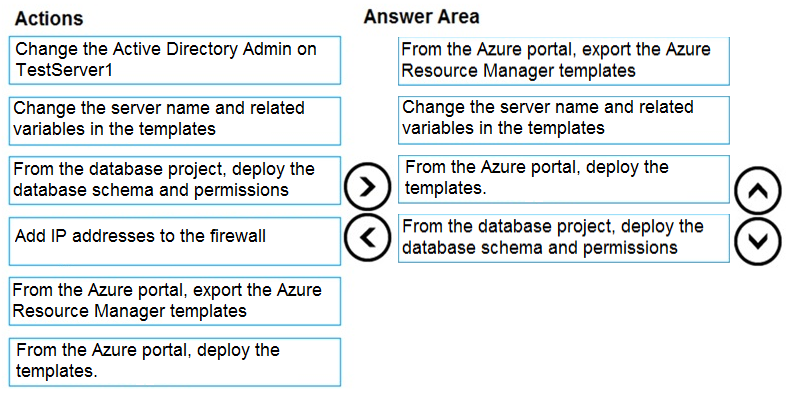
You have a resource group named App1Dev that contains an Azure SQL Database server named DevServer1. DevServer1 contains an Azure SQL database named DB1. The schema and permissions for DB1 are saved in a Microsoft SQL Server Data Tools (SSDT) database project.
You need to populate a new resource group named App1Test with the DB1 database and an Azure SQL Server named TestServer1. The resources in App1Test must have the same configurations as the resources in App1Dev.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Correct Answer:
HOTSPOT -
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named Account1.
You plan to access the files in Account1 by using an external table.
You need to create a data source in Pool1 that you can reference when you create the external table.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: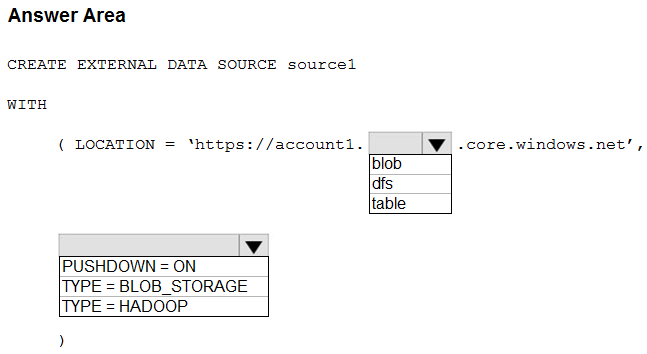
Correct Answer:
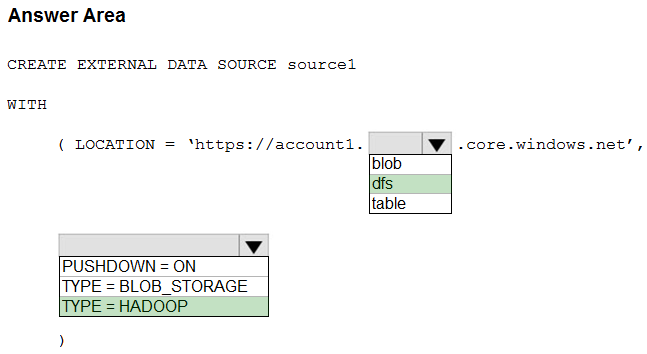
Box 1: dfs -
For Azure Data Lake Store Gen 2 used the following syntax:
http[s] <storage_account>.dfs.core.windows.net/<container>/subfolders
Incorrect:
Not blob: blob is used for Azure Blob Storage. Syntax:
http[s] <storage_account>.blob.core.windows.net/<container>/subfolders
Box 2: TYPE = HADOOP -
Syntax for CREATE EXTERNAL DATA SOURCE.
External data sources with TYPE=HADOOP are available only in dedicated SQL pools.
CREATE EXTERNAL DATA SOURCE <data_source_name>
WITH -
( LOCATION = '<prefix>://<path>'
[, CREDENTIAL = <database scoped credential> ]
, TYPE = HADOOP
)
[;]
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
HOTSPOT -
You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns:
✑ ProductID
✑ ItemPrice
✑ LineTotal
✑ Quantity
✑ StoreID
✑ Minute
✑ Month
✑ Hour
✑ Year
✑ Day
You need to store the data to support hourly incremental load pipelines that will vary for each StoreID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: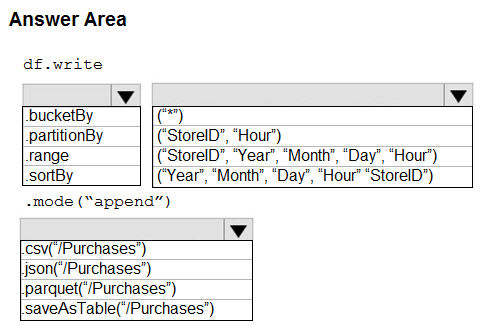
Correct Answer:
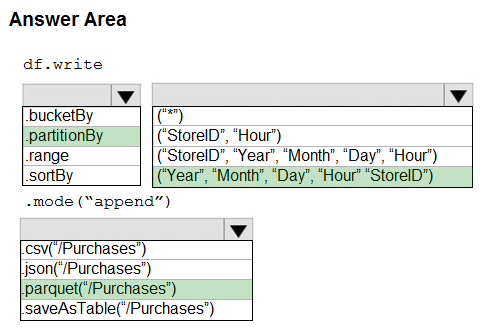
Box 1: .partitionBy -
Example:
df.write.partitionBy("y","m","d")
.mode(SaveMode.Append)
.parquet("/data/hive/warehouse/db_name.db/" + tableName)
Box 2: ("Year","Month","Day","Hour","StoreID")
Box 3: .parquet("/Purchases")
Reference:
https://intellipaat.com/community/11744/how-to-partition-and-write-dataframe-in-spark-without-deleting-partitions-with-no-new-data
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
Correct Answer:
D
🗳️
The partition count for an event hub in a dedicated Event Hubs cluster can be increased after the event hub has been created.
Incorrect Answers:
A: For Azure Event standard hubs, the partition count isn't changeable, so you should consider long-term scale when setting partition count.
Reference:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features#partitions
By buying Contributor Access for yourself, you will gain the following features:

